Kirigami: Lightweight Speech Filtering for Privacy-Preserving Activity Recognition using Audio
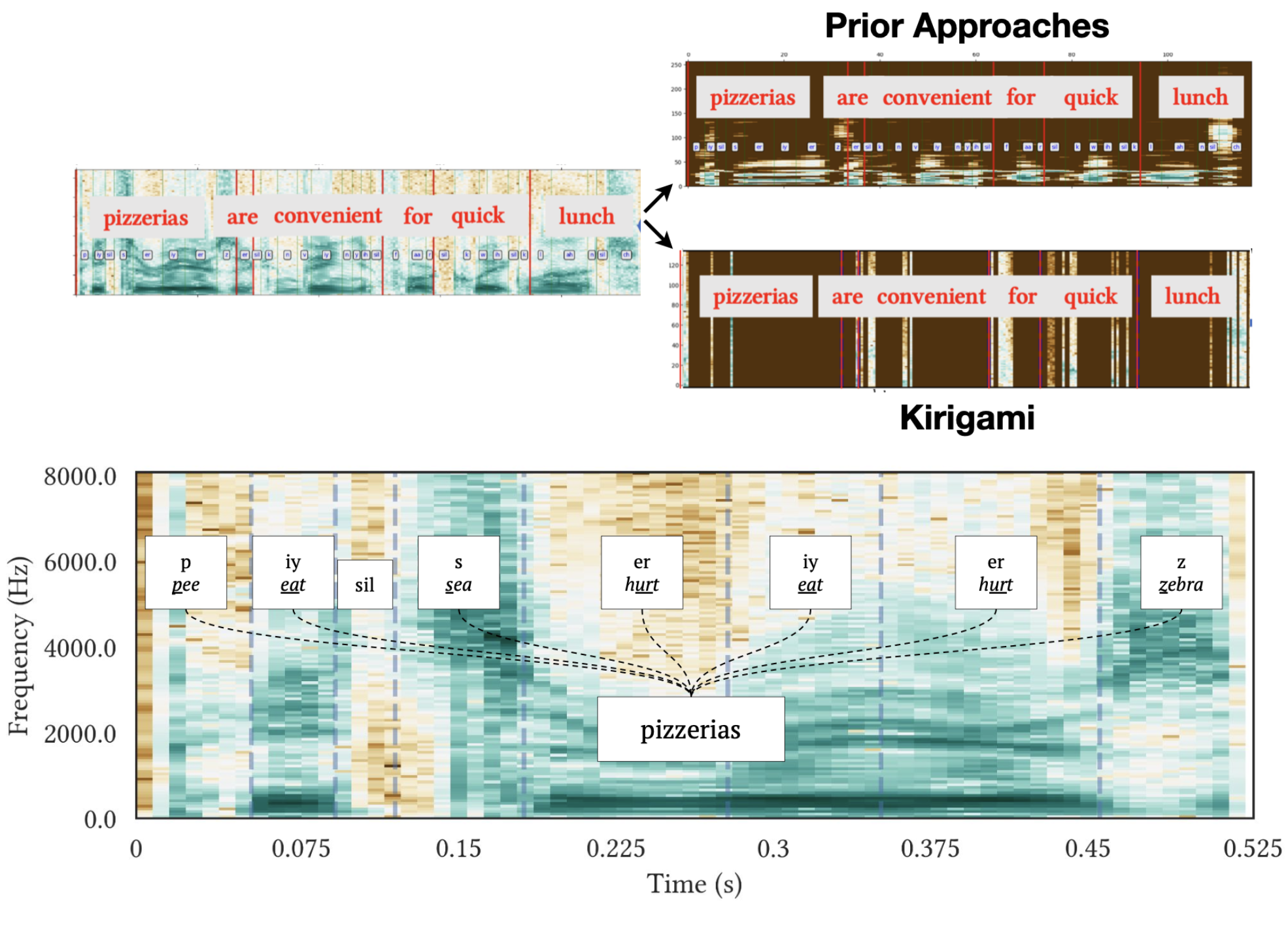
Audio-based human activity recognition (HAR) is very popular because many human activities have unique sound signatures that can be detected using machine learning (ML) approaches. These audio-based ML HAR pipelines often use common featurization techniques, such as extracting various statistical and spectral features by converting time domain signals to the frequency domain (using an FFT) and using them to train ML models. Some of these approaches also claim privacy benefits by preventing the identification of human speech. However, recent deep learning-based automatic speech recognition (ASR) models pose new privacy challenges to these featurization techniques. In this paper, we systematically evaluate various featurization approaches for audio data, assessing their privacy risks through metrics like speech intelligibility (PER and WER) while considering the utility tradeoff in terms of ML-based activity recognition accuracy. Our findings reveal the susceptibility of these approaches to speech content recovery when exposed to recent ASR models, especially under re-tuning or retraining conditions. Notably, fine-tuned ASR models achieved an average Phoneme Error Rate (PER) of 39.99% and Word Error Rate (WER) of 44.43% in speech recognition for these approaches. To overcome these privacy concerns, we propose Kirigami, a lightweight machine learning-based audio speech filter that removes human speech segments reducing the efficacy of ASR models (70.48% PER and 101.40% WER) while also maintaining HAR accuracy (76.0% accuracy). We show that Kirigami can be implemented on common edge microcontrollers with limited computational capabilities and memory, providing a path to deployment on a variety of IoT devices. Finally, we conducted a real-world user study and showed the robustness of Kirigami on a laptop and an ARM Cortex-M4F microcontroller under three different background noises.